一:问题引出 要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机 归属地不同省份输出到不同文件中(分区)
二:默认Partitioner分区 1 2 3 4 5 public class HashPartitioner <K, V> extends Partitioner <K, V> { public int getPartition (K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }
默认分区是根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制哪个 key存储到哪个分区。
三:自定义Partitioner 步骤 3.1 自定义类继承Partitioner,重写getPartition()方法 1 2 3 4 5 6 7 8 public class CustomPartitioner extends Partitioner <Text, FlowBean> { @Override public int getPartition (Text key, FlowBean value, int numPartitions) { … … return partition; } }
3.2 在Job驱动中,设置自定义Partitioner 1 job.setPartitionerClass(CustomPartitioner.class);
3.3 自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask 1 job.setNumReduceTasks(5 );
四:分区总结 (1)如果ReduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
(2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
(3)如 果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个 ReduceTask,最终也就只会产生一个结果文件 part-r-00000;
(4)分区号必须从零开始,逐一累加。
五:案例分析
例如:假设自定义分区数为5,则
(1)job.setNumReduceTasks(1);
(2)job.setNumReduceTasks(2);
(3)job.setNumReduceTasks(6); 会正常运行,只不过会产生一个输出文件 会报错 大于5,程序会正常运行,会产生空文件
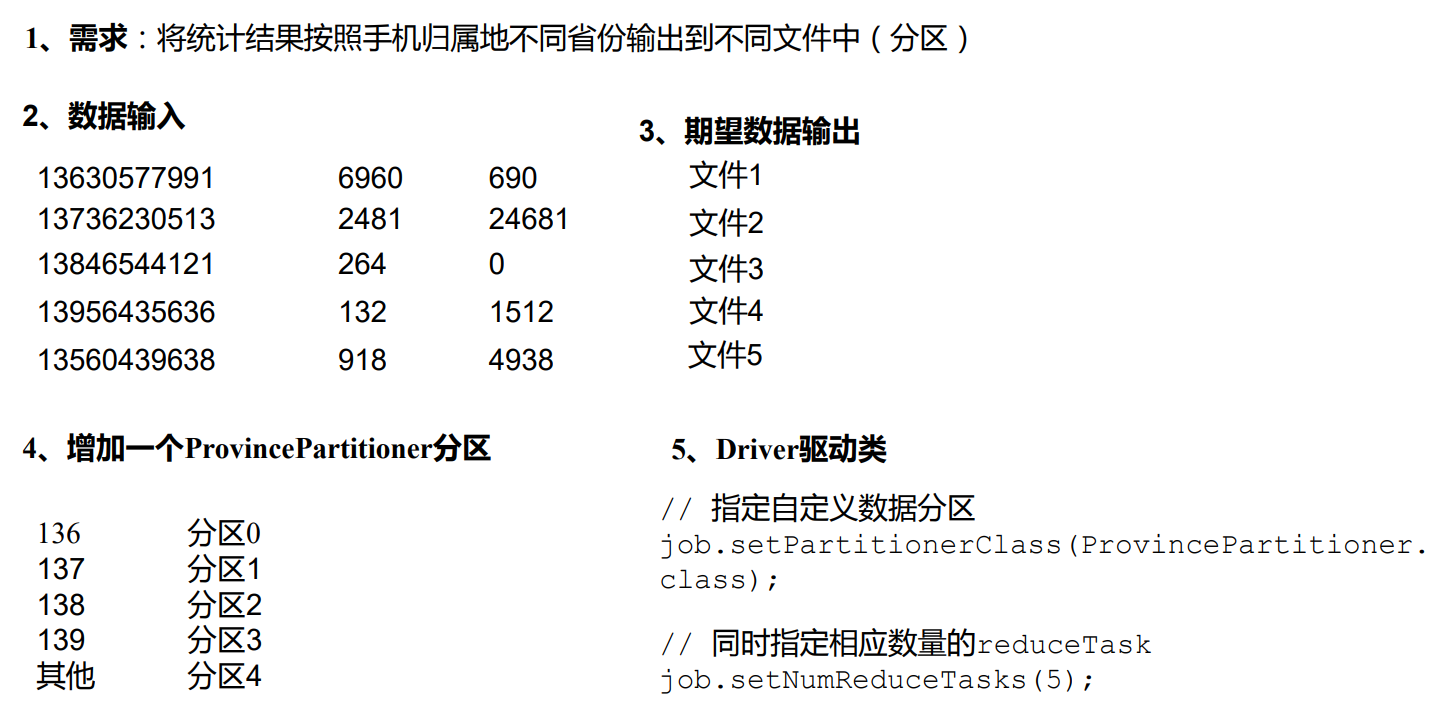
六:Partition 分区案例实操 6.1 需求 将统计结果按照手机归属地不同省份输出到不同文件中(分区);
(1)输入数据
(2)期望输出数据
手机号 136、137、138、139 开头都分别放到一个独立的 4 个文件中,其他开头的放到 一个文件中。
6.2 需求分析
6.3 代码实现 (1)增加分区类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package cn.aiyingke.mapreduce.partition;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Partitioner;public class ProvincePartitioner extends Partitioner <Text, FlowBean> { @Override public int getPartition (Text text, FlowBean flowBean, int i) { String phone = text.toString(); final String prePhone = phone.substring(0 , 3 ); int partition; switch (prePhone) { case "136" : partition = 0 ; break ; case "137" : partition = 1 ; break ; case "138" : partition = 2 ; break ; case "139" : partition = 3 ; break ; default : partition = 4 ; break ; } return partition; } }
(2)在驱动函数中增加自定义数据分区设置和 ReduceTask 设置 1 2 3 4 job.setPartitionerClass(ProvincePartitioner.class); job.setNumReduceTasks(5 );
(3)驱动器类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 package cn.aiyingke.mapreduce.partition;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class FlowDriver { public static void main (String[] args) throws IOException, InterruptedException, ClassNotFoundException { final Configuration configuration = new Configuration (); final Job job = Job.getInstance(); job.setJarByClass(FlowDriver.class); job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); job.setPartitionerClass(ProvincePartitioner.class); job.setNumReduceTasks(5 ); FileInputFormat.setInputPaths(job, new Path ("Y:\\Temp\\phone_data.txt" )); FileOutputFormat.setOutputPath(job, new Path ("Y:\\Temp\\output1234\\" )); final boolean b = job.waitForCompletion(true ); System.exit(b ? 0 : 1 ); } }
(4)Mapper 类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package cn.aiyingke.mapreduce.partition;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class FlowMapper extends Mapper <LongWritable, Text, Text, FlowBean> { private final Text outK = new Text (); private final FlowBean outV = new FlowBean (); @Override protected void map (LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException { final String line = value.toString(); final String[] split = line.split("\t" ); final String phone = split[1 ]; final String upFlow = split[split.length - 3 ]; final String downFlow = split[split.length - 2 ]; outK.set(phone); outV.setUpFlow(Long.parseLong(upFlow)); outV.setDownFlow(Long.parseLong(downFlow)); outV.setSumFlow(); context.write(outK, outV); } }
(5)Reducer 类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package cn.aiyingke.mapreduce.partition;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowReducer extends Reducer <Text, FlowBean, Text, FlowBean> { private final FlowBean outV = new FlowBean (); @Override protected void reduce (Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) throws IOException, InterruptedException { long totalUpFlow = 0 ; long totalDownFlow = 0 ; for (FlowBean value : values) { totalUpFlow += value.getUpFlow(); totalDownFlow += value.getDownFlow(); } outV.setUpFlow(totalUpFlow); outV.setDownFlow(totalDownFlow); outV.setSumFlow(); context.write(key, outV); } }
(6)实体类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package cn.aiyingke.mapreduce.partition;import lombok.Getter;import lombok.Setter;import org.apache.hadoop.io.Writable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;@Getter @Setter public class FlowBean implements Writable { private long upFlow; private long downFlow; private long sumFlow; public FlowBean () { } public void setSumFlow () { this .sumFlow = this .upFlow + this .downFlow; } @Override public void write (DataOutput dataOutput) throws IOException { dataOutput.writeLong(upFlow); dataOutput.writeLong(downFlow); dataOutput.writeLong(sumFlow); } @Override public void readFields (DataInput dataInput) throws IOException { this .upFlow = dataInput.readLong(); this .downFlow = dataInput.readLong(); this .sumFlow = dataInput.readLong(); } @Override public String toString () { return upFlow + "\t" + downFlow + "\t" + sumFlow; } }