
数仓项目-概念及架构
一:采集项目&数据仓库项目的区别
从功能角度:
- 采集:以数据为主,传输为主;
- 数仓:以数据的计算为主,同时也能存储数据;
从技术角度:
- 采集:flume、kafka、datax、maxwell
- 数仓:mysql、hdfs、spark、flink、mr、hive
二:数据库和数据仓库的区别
从名称上区分:
- 数据库:database(基础、核心的数据)
- 数据仓库:data warehouse(货栈、大商店、小卖店),注重于对外提供服务
从数据的来源区分:
- 数据库:企业中基础核心的业务数据
- 数据仓库:数据库中的数据
从数据存储的角度区分:
- 数据库:核心作用是查找业务数据
- 如何存储有利于查询:行式存储(底层使用索引),不能存储海量数据;
- 数据仓库:统计分析数据
- 如何存储有利于统计、分析:列式存储,可以存储海量数据;
从数据的价值区分:
- 数据库:保障全企业、全业务的正常运行;
- 数据仓库:将数据的统计的结果为企业的经营决策提供数据支撑;
- 数据仓库不是数据流转的终点,需要将统计的结果通过可视化呈现;
三:数据流转的过程
- 用户
- 业务服务器
- 数据存储:行为数据库(文件)
- 数据的统计分析:数据仓库
- 数据可视化
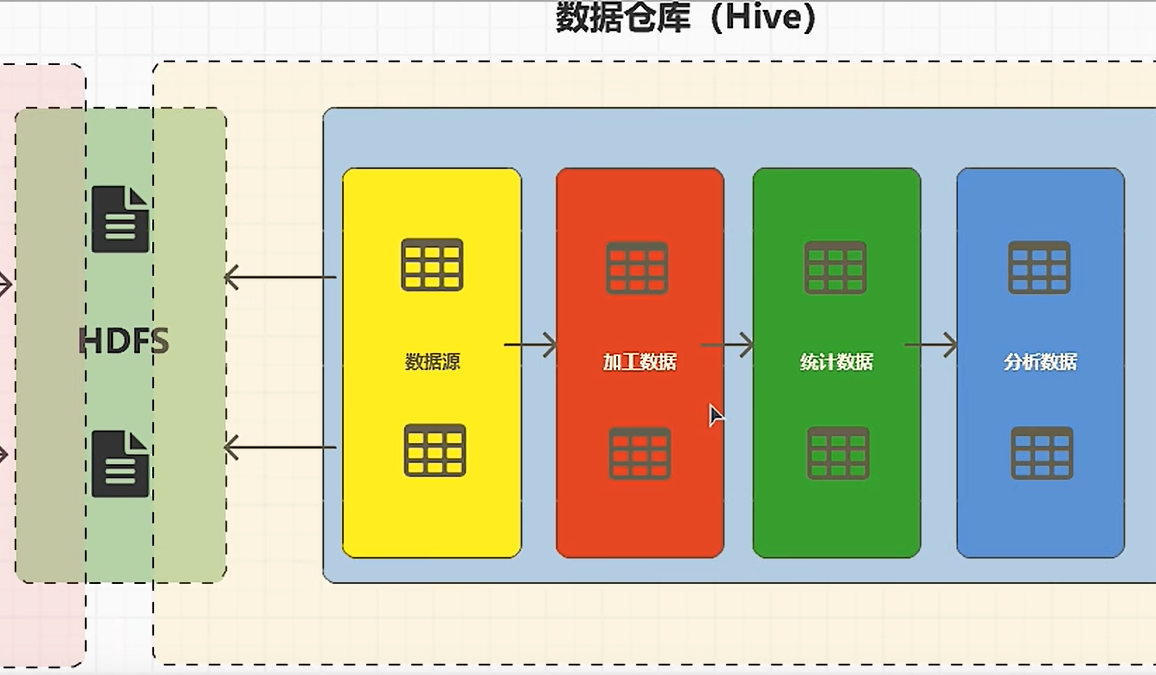
四:数据统计分析的基本步骤
确定数据源;
加工数据;(可以过滤、补全、脱敏等)
统计数据;
分析数据;
- spark on hive;(spark 解析 sql)
- hive on spark;(hive 解析 sql)
五:数据仓库-架构
如果将数据库(MySQL)直接作为数据仓库的数据源,存在的问题:
业务数据库的数据存储为行式存储,而数据仓库的数据要求为列式存储;
- 数据不能直接对接:行式数据转换为列式数据
业务数据库中存储的数据不是海量数据,但数据仓库要求为海量数据;
- 数据不能直接对接:数据量不够
数据库不是为数据仓库服务的
- 数据仓库在对接数据库数据时,会对数据库的性能造成影响;
- 数据仓库应该设计一个自己的数据源;
- 同步数据库数据,为了代替和补充数据库;
- 汇总数据库数据(海量数据)
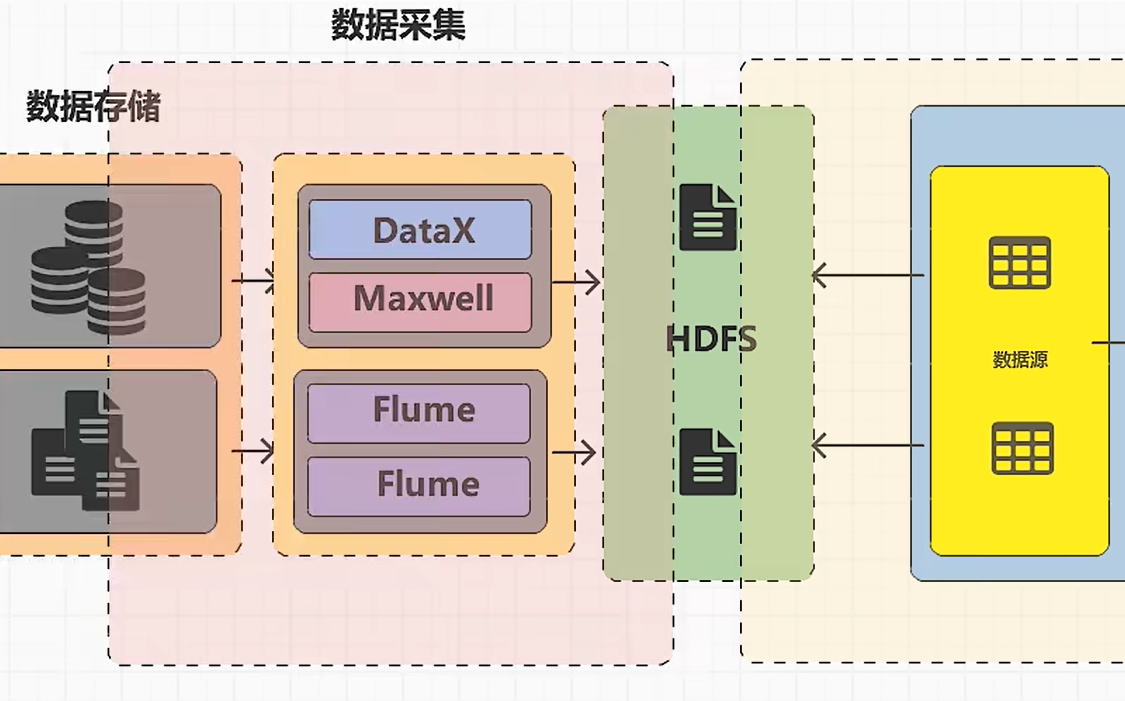
六:数据采集和数据仓库-架构
数据仓库中的数据源需要从数据库中周期性(以天为单位)同步;一般情况下,这个同步的过程,称之为“采集”;
数据采集的时候,如果想要将数据同步到数据仓库的数据源,那么就必须知道业务数据库的表结构;那么采集项目和数据仓库项目就存在耦合性,因此需要解耦合,解耦合的核心就在于增加中间件;数据源为文件或者表,因此最好的中间件就是HDFS;
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 爱影客!

