
Kafka 概述
一:定义
Kafka 传统定义:Kafka 是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据的实时处理场景。
发布/订阅:消息的发布者不会将消息直接发送给消息的订阅者,而是将发送的消息分为不同的类别,订阅者只接受感兴趣的消息。
Kafka 愿景定义:Kafka 是一个开源的分布式事件流平台,被多数公司用于高性能数据管道、流分析、数据集成和关键任务应用。
二:消息队列
在大数据领域通常采用 Kafka 作为消息队列。
2.1 传统消息队列的应用场景
传统的消息队列主要应用于:缓存/消峰、解耦和异步通信。
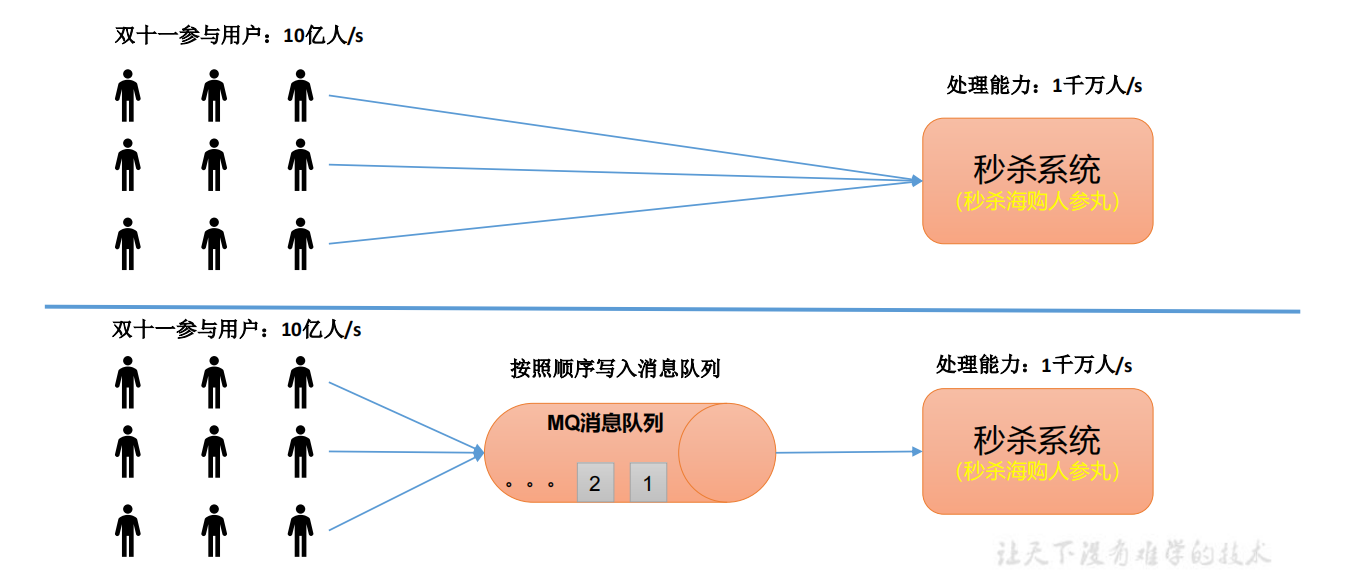
缓存/消峰:
有助于控制和优化数据流系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
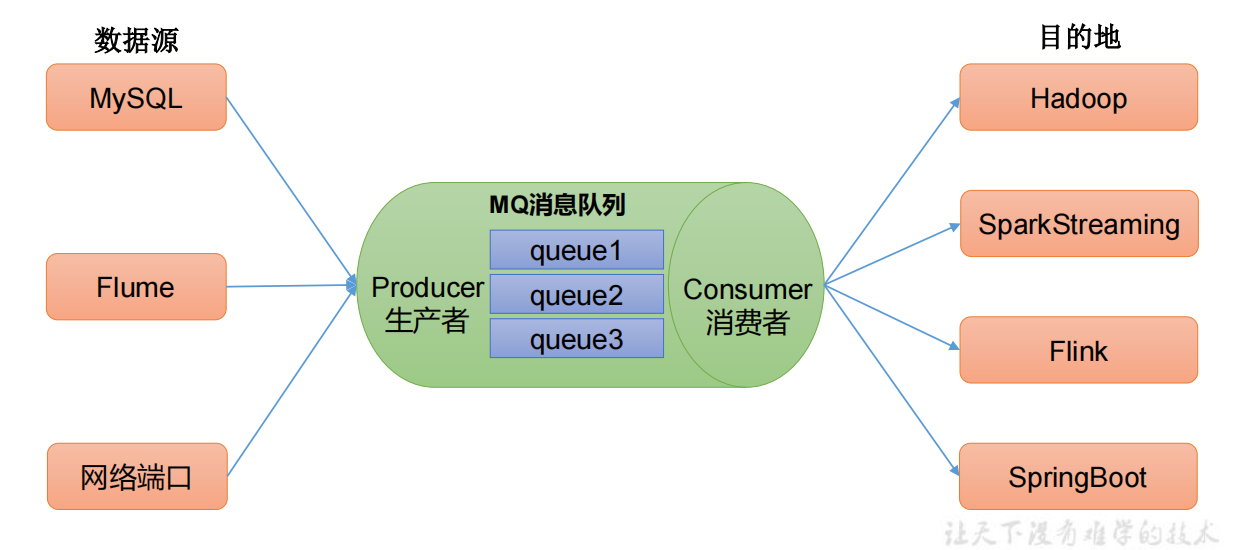
解耦:
允许独立的扩展或者修改两边的处理过程,只要确保他们遵循同样的数据接口约束。
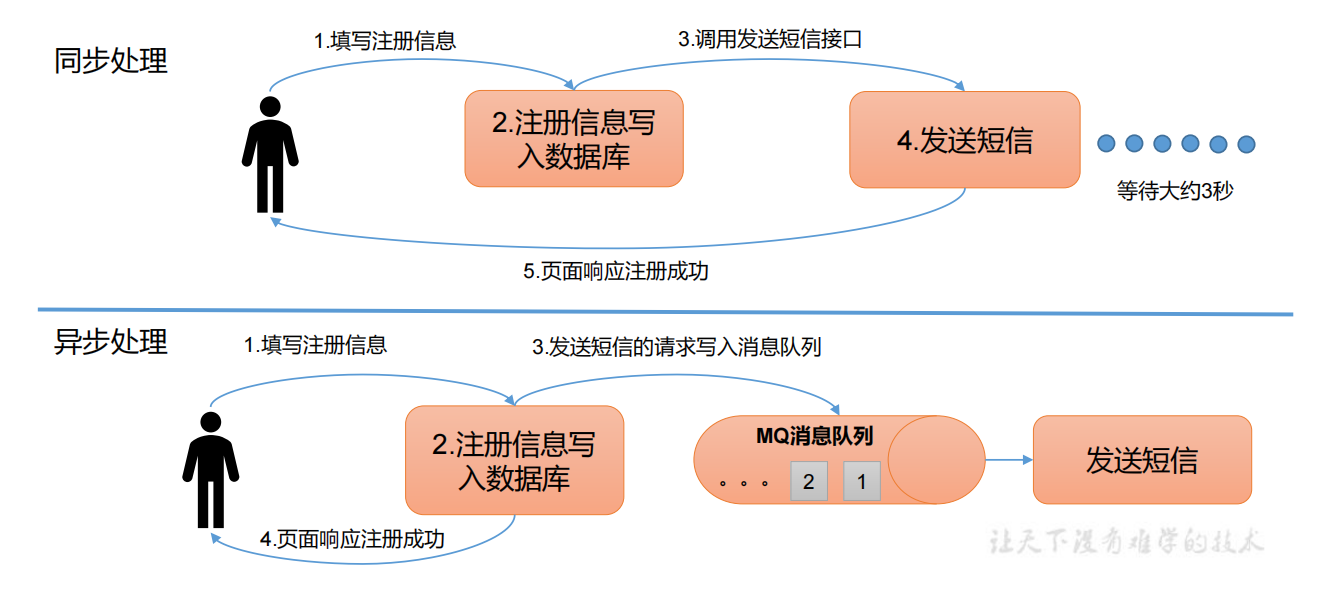
异步通信:
允许用户把消息放入队列中,但不立即处理它,然后在需要的时候再处理它们。
2.2 消息队列的两种模式
点对点模式:
消费者主动拉去消息,收到消息后清除消息。

发布/订阅模式:
- 可以有多个topic主题;
- 消费者消费数据后,不删除数据;
- 每个消费者相互独立,都可以消费到数据。

三:Kafka 基础架构
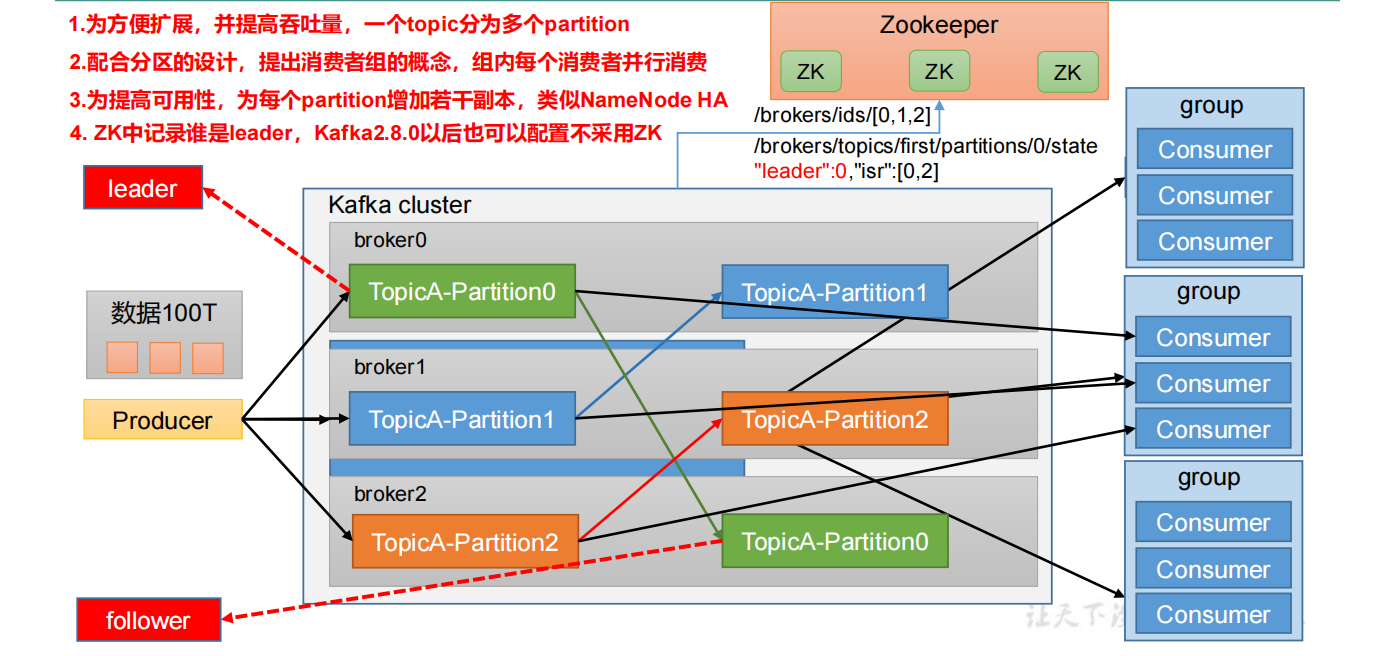
(1)Producer:消息生产者,向 Kafka broker 发消息的客户端。
(2)Consumer:消息消费者,向 Kafka broker 取消息的客户端。
(3)Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
(4)Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
(5)Topic:可以理解为一个队列,生产者和消费者面向的都是一个topic。
(6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker (服务器)上,一个 topic 可以分为多个 partition,每个 parition 是一个有序的队列。
(7)Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower。
(8)Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
(9)Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和 Leader 数据同步。Leader 发生故障时,某一个 Follower 会成为新的 Leader。
