
Spark 常用算子
一:算子概述
1.1 什么是算子?
英文:Operator
狭义:一个函数空间到另一个函数空间的映射
广义:一个空间到另个一个空间的映射
白话:一个事物从一个状态到另一个状态的过程
实质:映射,即关系
1.2 算子的重要作用
- 算子越多,灵活性越高,编程的可选方式就越多
- 算子越多,表现能力强,可以灵活应对各种复杂场景
1.3 MapReduce 和 Spark 算子比较
- MapReduce 只有2个算子,map和reduce,绝大多数场景下,需要复杂的编程来完成业务需求
- Spark 有80多个算子,可以灵活组合应对不同的业务场景
二:Spark算子
2.1 转换算子(transformation)
此种算子不会真正的触发提交作业,只有作业被提交后才会触发转换计算
- value型转换算子(处理的数据项是value型)
- 输入分区:输出分区 = 1 : 1
- map算子
- flatMap算子
- mapPartitions算子
- 输入分区:输出分区 = n : 1
- union算子
- cartesian算子
- 输入分区 :输出分区 = n : n
- groupBy算子
- 输出分区为输入分区的子集
- filter算子
- distinct算子
- substract算子
- sample算子
- takeSample算子
- cache型算子
- cache算子
- persist算子
- 输入分区:输出分区 = 1 : 1
- key-value型转换算子(处理的数据类型是key-value型)
- 输入分区:输出分区 = 1: 1
- mapValues 算子
- 对单个RDD聚集
- combineByKey算子
- reduceByKey算子
- partitionBy算子
- 对两个RDD聚合
- cogroup算子
- 连接
- join算子
- leftOutJoin算子
- rightOutJoin算子
- 输入分区:输出分区 = 1: 1
2.2 行动算子(action)
这种算子会触发sparkContent提交作业;
- 无输出(不生成文件)
- foreach算子
- HDFS
- saveAsTextFile算子
- saveAsObjectFile算子
- scala集合和数据类型
- collect算子
- collectAsMap算子
- reduceByKeyLocally算子
- lookup算子
- count算子
- top算子
- reduce算子
- fold算子
- aggregate算子
三:常见算子的应用场景
3.1 转换算子(transformation)
3.1.1 value型转换算子
(1)map
类比mapreduce中的map操作,给定一个输入,由map函数操作后,成为一个新的元素输出;
1 | val first = sc.parallelize(List("Hello","Word","你好","世界"),2) |

1 | val first = sc.parallelize(1 to 5,2) |

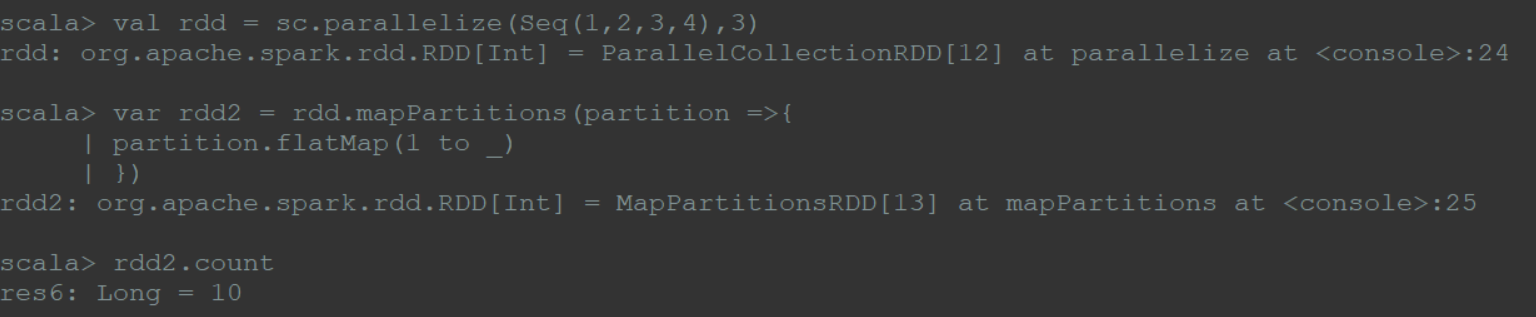
(2)flatMap
给定一个二维的输入(线式输入),将返回的所有结果打平成一个一维的集合结构(点式集合输出);
1 | val first = sc.parallelize(1 to 5,2) |

1 | val first = sc.parallelize(List("one","two","three"),2) |

1 | val first = sc.parallelize(List("one","two","three"),2) |

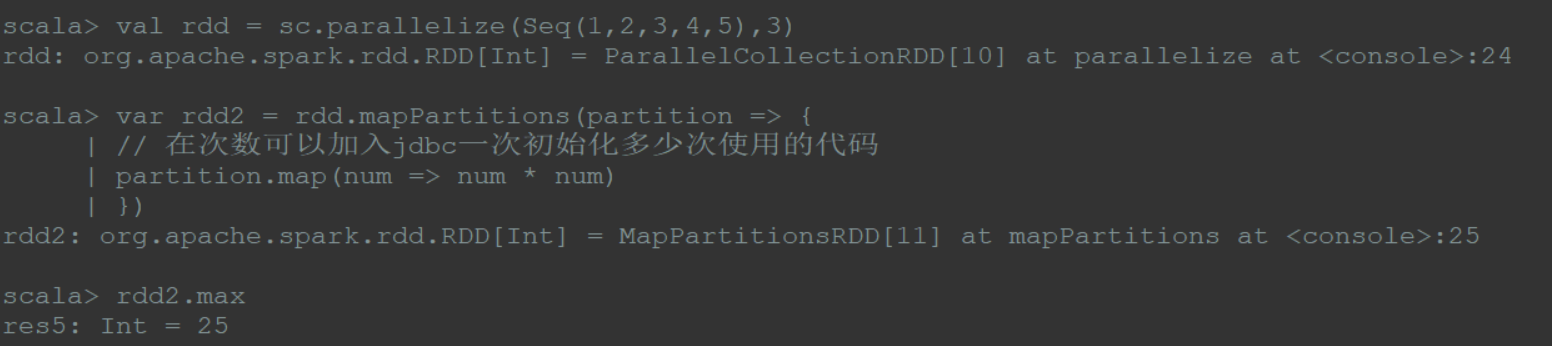
(3)mapPartitions
以分区为单位进行计算处理;
在map过程中,需要频繁创建额外对象时,如文件输出流操作、jdbc操作、socket操作,使用mapPartitions算子;
1 | val rdd = sc.parallelize(Seq(1,2,3,4,5),3) |
1 | val rdd = sc.parallelize(Seq(1,2,3,4),3) |
(4)glom
以分区为单位,将每个分区的值形成一个数组;
1 | val a = sc.parallelize(Seq("one","two","three","four","five"),3) |

由上诉得到:分组的依据是平均分组
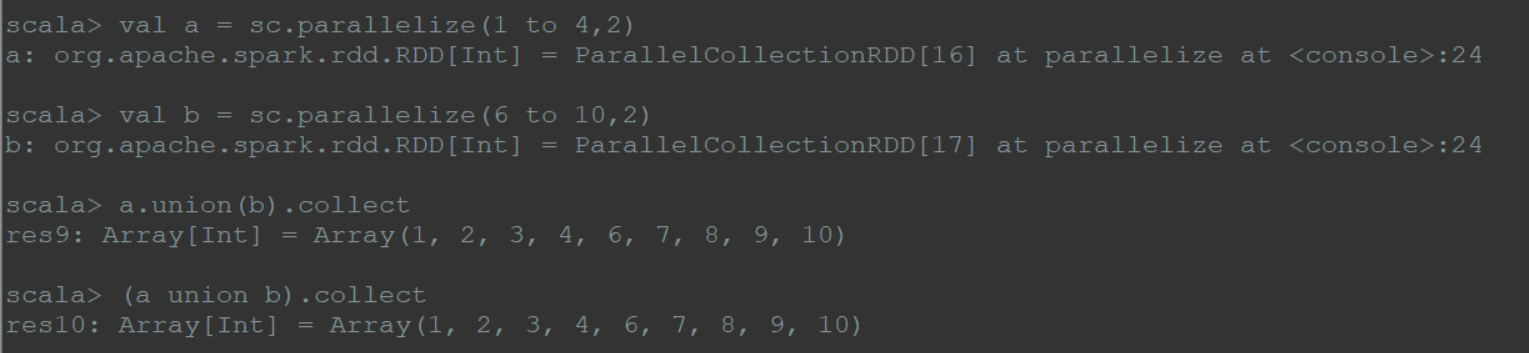
(5)union
将2个rdd合并成一个rdd,不去重;有时可能会发生多个分区合并成一个分区的情况。
1 | val a = sc.parallelize(1 to 4,2) |

1 | (a union b).collect |
(6)groupBy
输入分区和输出分区 n : n型
1 | val a = sc.parallelize(Seq(1,2,3,4,5,56,67),3) |

(7)filter
输出为输入的子集;
1 | val a = sc.parallelize(1 to 4,3) |

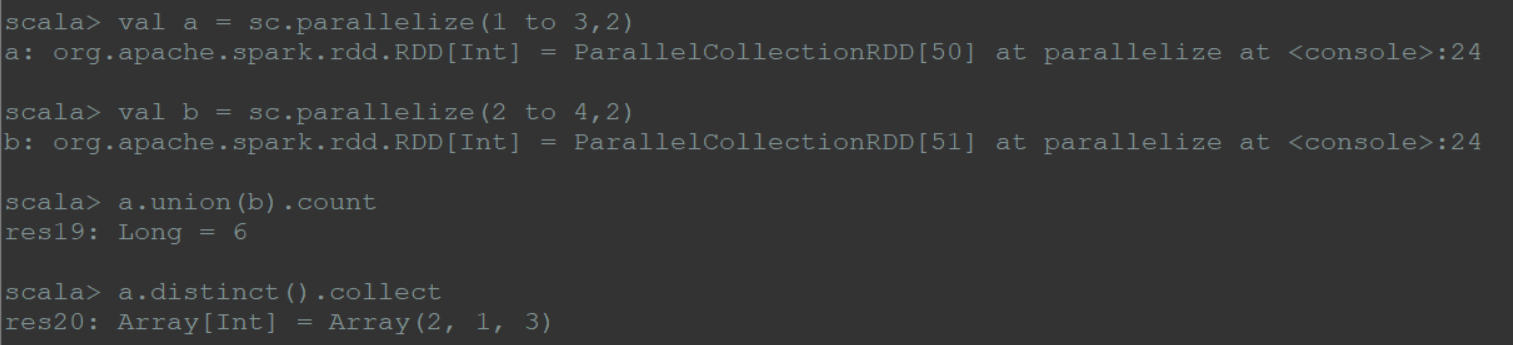
(8)distinct
输出分区为输入分区的子集,全局去重;
1 | val a = sc.parallelize(1 to 3,3) |

1 | val c = sc.parallelize(List("小红","消化","不良","消化")) |

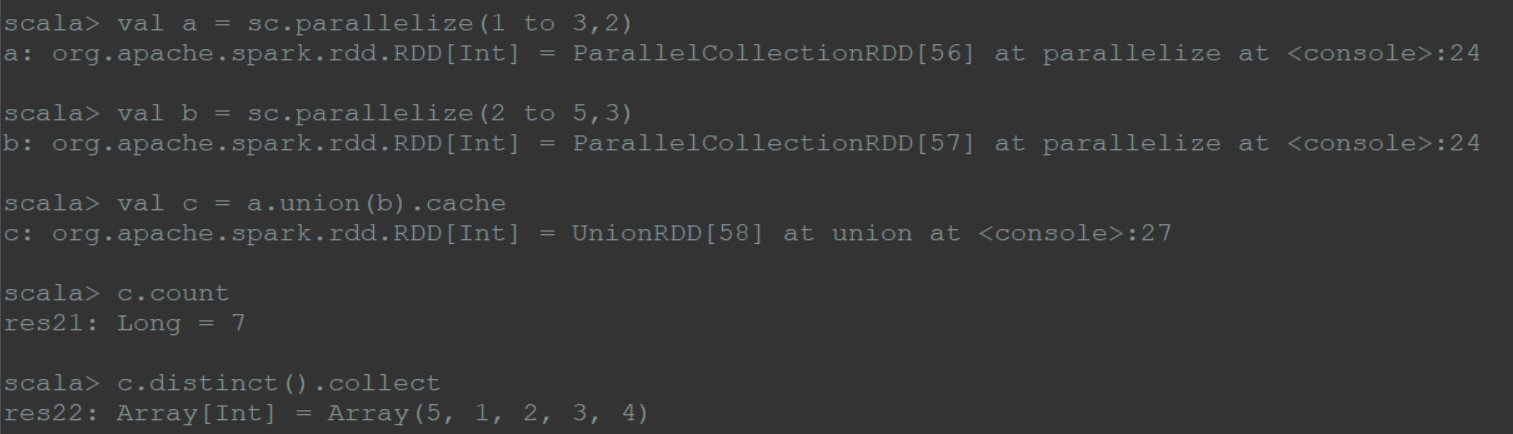
(9)cache
cache将rdd元素从磁盘缓存到内存中,数据反复被使用的场景使用
1 | val a = sc.parallelize(1 to 3,2) |
1 | val a = sc.parallelize(1 to 3,2) |
3.1.2 key-value型转换算子
(1)mapValues
输入分区:输出分区 = 1 : 1
针对key-value型数据中的value进行map操作,而不对key进行处理;
1 | val first = sc.parallelize(List(("张三",1),("李四",2),("王五",3)),2) |

(2)★ combineByKey ★
定义
def combineByKey [C] (
createCombiner: (V) => C,
mergeValue: (C,V) => C,
mergeCombiners: (C,C) => C): RDD[(String, C)]
元素
createCombiner对每个分区内的同组元素如何聚合,形成一个累加器
mergeValue 将累加器与新遇到的值进行合并的方法
mergeCombiners 每个分区都是独立处理,故同一个键可以有多个累加器。如果两个或者多个分区都对应同一个键的累加器,用方法将各个分区的结果进行合并。
1 | val first = sc.parallelize(List(("张一",4),("张一",2),("张三",3)),2) |

(3)reduceByKey
按key聚合后对组进行规约处理,求和
1 | val first = sc.parallelize(List("小米","华为","小米","华硕","很郁闷"),2) |

(4)join
对 key-value 结构的rdd进行按key的join操作,最后将V部分做flatMap打平操作
1 | val first = sc.parallelize(List(("张三",11),("李四",12)),2) |

3.2 行动算子 action
该类型算子会触发SparkContext提交作业,触发RDD DAG的执行
(1)无输出型,不落地本地文件或hsfs文件
foreach算子
1 | val first = sc.parallelize(List("小米","华为","华米","小米","苹果","华米","三星"),2) |

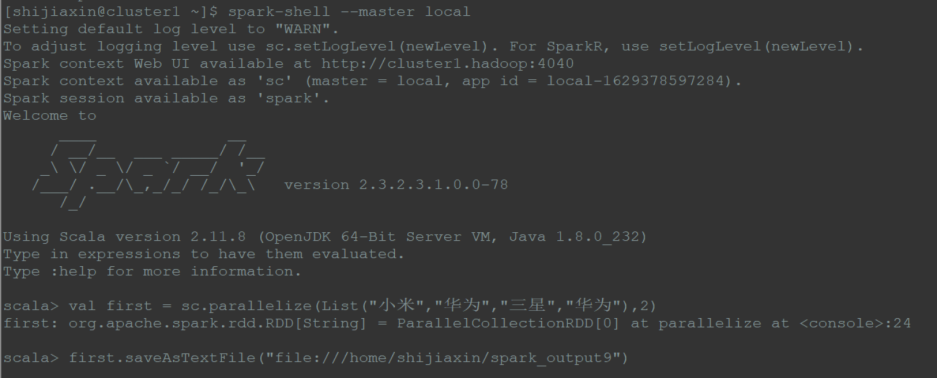
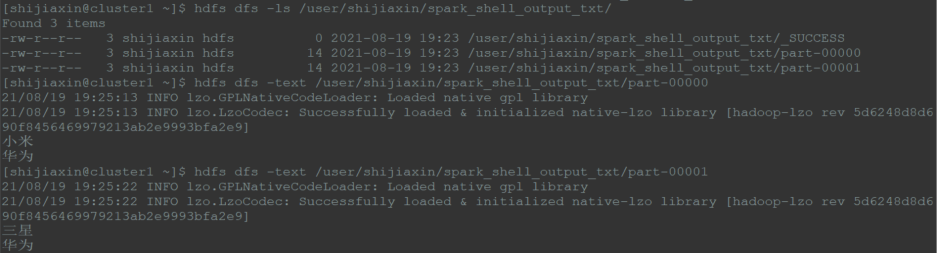
(2)HDFS输出型
saveAsTextFile算子
1 | val first = sc.parallelize(List("小米","华为","三星","华为"),2) |
1 | =================killed================== |
(3)scala集合和数据类型
collect算子
相当于toArray操作,将分布式RDD返回成为一个scala array数组结果,实际是Driver所在的机器节点
1 | val first = sc.parallelize(List("小米", "华为", "花粉", "苹果" ), 2) |

(4)collectAsMap算子
相当于 toMap 操作,将分布式 RDD的 kv 对形式,返回成为一个 scala map集合,实际上Driver所在的机器节点,在处理
1 | val first = sc.parallelize(List(("张一",1),("礼仪",1),("张一",3),("白虎",3)),2) |

(5)lookup算子
对键值对类型的 RDD操作,返回指定key对应的元素形成的Seq
1 | val first = sc.parallelize(List("小米","爱华为","爱尔兰","cs"),2) |

(6)reduce算子
先对两个元素进行reduce函数操作,然后将结果和迭代器取出的下一个元素进行reduce函数操作,直到迭代器遍历完所有元素,得到最后结果
1 | val a = sc.parallelize(1 to 3, 3) |

1 | val a = sc.parallelize(List(("one",1),("two",2),("three",3)),3)(最后的3 代表3个分区) |

(7)fold算子fold算子:
def fold (zeroValue: T)(op: (T, T) => T) : T
先对rdd分区的每一个分区进行op函数
在调用op函数过程中将zeroValue参与计算
最后在对所有分区的结果调用op函数,同事在此处进行zeroValue再次参与计算
1 | // 和是41 公式:(1+2+3+4+5+6+10)+10 |

1 | // 和是51 公式:(1+2+3+10)+(4+5+6+10)+10 |

1 | // 和是61 公式:(1+2+10)+(3+4+10)+(5+6+10)+10 |

四:其他常用算子
- cartesian算子
- subtract算子
- sample算子
- takeSample算子
- persist算子
- cogroup算子
- leftOuterJoin算子
- rightOuterJoin算子
- saveAsObjectFile算子
- count算子
- top算子
- aggregate算子

