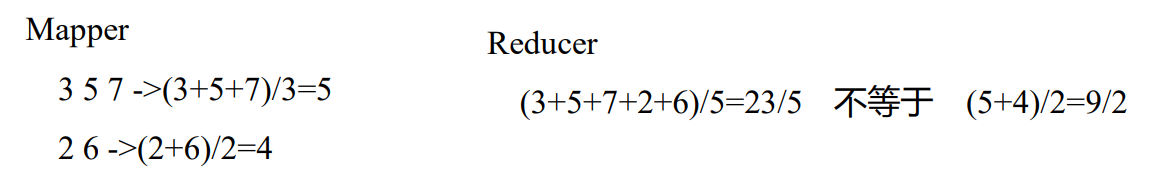一:Combiner合并概述 (1)Combiner是MR程序中Mapper和Reducer之外的一种组件。
(2)Combiner组件的父类就是Reducer。
(3)Combiner和Reducer的区别在于运行的位置
Combiner是在每一个MapTask所在的节点运行
Reducer是接收全局所有Mapper的输出结果
(4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
(5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv 应该跟Reducer的输入kv类型要对应起来。以下求平均值就不能够使用 Combiner;
二:自定义 Combiner 实现步骤 2.1 自定义一个 Combiner 继承 Reducer,重写 Reduce 方法 1 2 3 4 ``` ## 2.2 在 Job 驱动类中设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 # 三:Combiner 合并案例实操 ## 3.1 需求 统计过程中对每一个 MapTask 的输出进行局部汇总,以减小网络传输量即采用 Combiner 功能。 ### (1)数据输入 - data.txt ### (2)期望输出数据 - Combine 输入数据多,输出时经过合并,输出数据降低。 ## 3.2 需求分析 对每一个MapTask的输出局部汇总(Combiner);  ## 3.3 代码实现(方案一) ### (1)增加一个 WordCountCombiner 类继承 Reducer ```java package cn.aiyingke.mapreduce.combiner; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Author: Rupert Tears * Date: Created in 19:18 2022/12/18 * Description: Thought is already is late, exactly is the earliest time. */ public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> { private final IntWritable outV = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { // 定义聚合变量 int sum = 0; // 遍历求和 for (IntWritable value : values) { sum += value.get(); } // 封装 outKV outV.set(sum); // 写出 context.write(key, outV); } }
(2)在 WordcountDriver 驱动类中指定 Combiner 1 2 job.setCombinerClass(WordCountCombiner.class);
3.4 代码实现(方案二) (1)将 WordcountReducer 作为 Combiner 在 WordcountDriver 驱动类中指定 1 job.setCombinerClass(WordCountReducer.class);
3.5 代码汇总 (1)驱动器类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 package cn.aiyingke.mapreduce.combiner;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver { public static void main (String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration, "WordCount-MR" ); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class); job.setCombinerClass(WordCountCombiner.class); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(CombineTextInputFormat.class); CombineTextInputFormat.setMaxInputSplitSize(job, 4194304 ); FileInputFormat.addInputPath(job, new Path ("Y:\\Temp\\data.txt" )); FileOutputFormat.setOutputPath(job, new Path ("Y:\\Temp\\asdsad" )); System.exit(job.waitForCompletion(true ) ? 0 : 1 ); } }
(2)Mapper 类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package cn.aiyingke.mapreduce.combiner;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;import java.util.StringTokenizer;public class WordCountMapper extends Mapper <Object, Text, Text, IntWritable> { IntWritable intWritable = new IntWritable (1 ); Text text = new Text (); @Override protected void map (Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { StringTokenizer stringTokenizer = new StringTokenizer (value.toString(), "," ); while (stringTokenizer.hasMoreTokens()) { String word = stringTokenizer.nextToken(); text.set(word); context.write(text, intWritable); } } }
(3)Reducer 类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package cn.aiyingke.mapreduce.combiner;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer <Text, IntWritable, Text, IntWritable> { IntWritable sumIntWritable = new IntWritable (); @Override protected void reduce (Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0 ; for (IntWritable val : values) { count += val.get(); } sumIntWritable.set(count); context.write(key, sumIntWritable); } }
(4)Combiner 类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package cn.aiyingke.mapreduce.combiner;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountCombiner extends Reducer <Text, IntWritable, Text, IntWritable> { private final IntWritable outV = new IntWritable (); @Override protected void reduce (Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0 ; for (IntWritable value : values) { sum += value.get(); } outV.set(sum); context.write(key, outV); } }
1 2 3 // 日志输出 Combine input records=6 Combine output records=3