
Dirbuster 使用教程
一:概述
DirBuster 一款网站目录文件扫描工具,支持全部的 Web 目录扫描方式,用于探测 web 服务器上的目录和隐藏文件的。它既支持网页爬虫方式扫描,也支持基于字典暴力扫描,还支持纯暴力扫描。该工具使用 java 语言编写,提供命令行和图形界面两种模式。其中,图形界面模式功能更为强大。用户不仅可以指定纯暴力扫描的字符规则,还可以设置以 URL 模糊方式构建网页路径。同时,用户还对网页解析方式进行各种定制,提高网页解析效率。
二:命令
2.1 启动
1 | 命令行启动 |
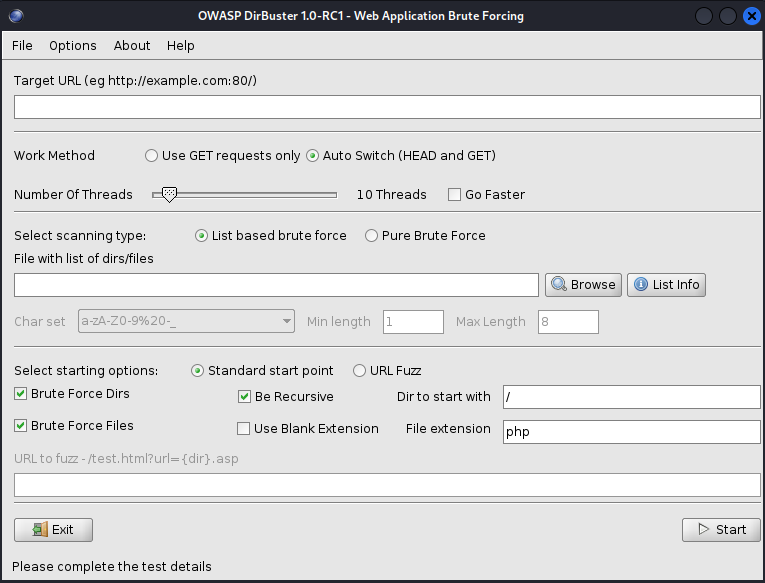
2.2 配置相关参数
- Target URL:目标ip地址或者域名,默认端口80,特殊端口需要补全
- Work Method:请求方式,使用 GET 请求或者 HEAD 和 GET 自动切换
- Number Of Threads:选择线程数,用于执行暴力破解的线程数,取决于攻击机的计算机硬件。
- Select scanning type:选择字典类型
- List based brute force:基于列表的暴力
- Pure Brute Force:纯粹的暴力(自动生成,无需配置字典)
- File with list of dirs/files:带有目录/文件列表的文件
- Select starting options:选择扫描方式
- Standard start point:标准起点
- Brute Froce Dirs:纯暴力目录
- Brute Froce Files:纯暴力文件
- Be Recursive:递归
- Use Blank Extension:延伸,使用空白拓展名
- Dir to start with:开始路径
- File extension:文件拓展名
- URL Fuzz (URL 模糊)
- {dir}:表示在 dir 前后可以随意拼接想要的目录或者后缀;
- 例如:”/admin/{dir}.html”,表示扫描admin目录下的所有html文件;
- Standard start point:标准起点
2.3 执行
点击 start 开始;
2.4 查看结果
- scan information:扫描信息
- Rseult - List View:结果列表
- Result - Tree View:结果树
- Errors:错误
2.5 常见响应
- 200:文件存在
- 404:服务器中不存在该文件
- 301:这是重定向到给定的URL
- 401:访问此文件需要身份验证;
- 403:请求有效但服务器拒绝响应;
2.6 导出
Report:导出报告
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 爱影客!

