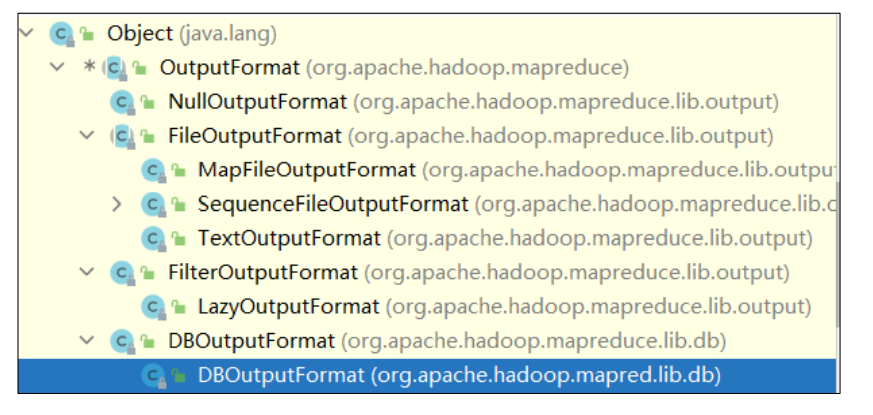
1.1 概述 OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了 OutputFormat 接口。下面我们介绍几种常见的OutputFormat实现类。
1.3 默认输出格式TextOutputFormat (1) 应用场景 例如:输出数据到MySQL/HBase/Elasticsearch等存储框架中。
自定义一个类继承FileOutputFormat
改写RecordWriter,具体改写输出数据的方法write()
2.1 需求 过滤输入的 log 日志,包含 aiyingke 的网站输出到 e:/aiyingke.log,不包含 aiyingke 的网站输出到 e:/other.log;
(1)输入数据
(2)期望输出数据
2.2 需求分析
需求
输入数据
输出数据
自定义一个 OutputFormat 类
创建一个类LogRecordWriter继承RecordWriter
创建两个文件的输出流:aiyingke,other
如果输入数据包含aiyingke,输出到aiyingkeOut流 如果不包含aiyingke,输出到otherOut流
驱动类 Driver
要将自定义的输出格式组件设置到job中
job.setOutputFormatClass(LogOutputFormat.class) ;
2.3 代码实现 (1)编写 LogMapper 类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package cn.aiyingke.mapreduce.outputformat;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class LogMapper extends Mapper <Object, Text, Text, NullWritable> { @Override protected void map (Object key, Text value, Mapper<Object, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { context.write(value, NullWritable.get()); } }
(2)编写 LogReducer 类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package cn.aiyingke.mapreduce.outputformat;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class LogReducer extends Reducer <Text, NullWritable, Text, NullWritable> { @Override protected void reduce (Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException { for (NullWritable value : values) { context.write(key, NullWritable.get()); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package cn.aiyingke.mapreduce.outputformat;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.RecordWriter;import org.apache.hadoop.mapreduce.TaskAttemptContext;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LogOutputFormat extends FileOutputFormat <Text, NullWritable> { @Override public RecordWriter<Text, NullWritable> getRecordWriter (TaskAttemptContext job) throws IOException, InterruptedException { LogRecordWriter lrw = new LogRecordWriter (job); return lrw; } }
(4)编写 LogRecordWriter 类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package cn.aiyingke.mapreduce.outputformat;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IOUtils;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.RecordWriter;import org.apache.hadoop.mapreduce.TaskAttemptContext;import java.io.IOException;public class LogRecordWriter extends RecordWriter <Text, NullWritable> { private final FSDataOutputStream otherOut; private final FSDataOutputStream aiyingkeOut; public LogRecordWriter (TaskAttemptContext job) { try { final FileSystem fileSystem = FileSystem.get(job.getConfiguration()); aiyingkeOut = fileSystem.create(new Path ("Y:\\Temp\\logOut\\aiyingke\\aiyingke.log" )); otherOut = fileSystem.create(new Path ("Y:\\Temp\\logOut\\other\\other.log" )); } catch (IOException e) { throw new RuntimeException (e); } } @Override public void write (Text text, NullWritable nullWritable) throws IOException, InterruptedException { final String line = text.toString(); if (line.contains("aiyingke" )) { aiyingkeOut.writeBytes(line + "\n" ); } else { otherOut.writeBytes(line + "\n" ); } } @Override public void close (TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { IOUtils.closeStream(aiyingkeOut); IOUtils.closeStream(otherOut); } }
(5)编写 LogDriver 类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 package cn.aiyingke.mapreduce.outputformat;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LogDriver { public static void main (String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration configuration = new Configuration (); Job job = Job.getInstance(configuration, "Log" ); job.setJarByClass(LogDriver.class); job.setMapperClass(LogMapper.class); job.setReducerClass(LogReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setOutputFormatClass(LogOutputFormat.class); FileInputFormat.addInputPath(job, new Path ("Y:\\Temp\\log\\" )); FileOutputFormat.setOutputPath(job, new Path ("Y:\\Temp\\logOut\\" )); System.exit(job.waitForCompletion(true ) ? 0 : 1 ); } }